Modern ETL and Data Warehouse Stack
09 Mar 2021Just some thoughts on a modern ETL and data warhouse stack that is:
- Managed. Low overhead, serverless when possible.
- Infinitely scalable. Easily adding processing resources and storage capacity.
- Modular. Easy to add new sources, fault tolerant across pipelines.
- Batch. Batch latency should be scalable, with the ability to shorten batch length to provide sub-hour updates.
- Modeled. The final product should not be soupy lake of data files we need to pre-process before using.
Extract
To go fully managed, a service like Stitch provides the easiest solution for extracting data from source systems. I’m personally not a huge fan of a fully-SaaS extract layer since there will always be something that isn’t supported by the service, so now you’re paying the premium for managed and you need to run your own custom extracts as well.
I’d prefer to implement a modular extract using Singer, the open source framework Stitch is built on. This would provide most of the benefits of using Stitch (they don’t open source some of their more profitable integrations) while also allowing for flexibility for custom integrations using the same tap and target framework.
To make a custom Singer-based extract layer more managed, it could be deployed as container flows to a managed container service like AWS ECS or GKE.
Transform and Load
The most scalable transformation solution is no transform. Storing data in raw extract format (which, if using Singer, should be consistent in terms of file type and structure) and building a data lake on top of it takes no processing. While there are advantages to this solution, I don’t think it fits our criteria:
- Traditional partitioning structures prohibit scaling batch latency. Once you start to partition your data into dates, changing to hourly batches is going to cause problems.
- Data lakes can be modeled, but relational databases must be. Using a warehouse will enforce our final requirement by default.
If data lakes are out, we have two remaining options: transform and load, or load and transform.
Transform and Load
Using an intermediary processing layer, data is first transformed to the final modeled state, then loaded into the warehouse. The practicality of this approach depends on the desired state of the data. If the model is a traditional star schema with fact and dimension tables, the intermediary step could get very complex.
The managed options for the intermediary processing layer are plentiful. Amazon offers EMR for Hadoop and Spark jobs, and Glue for a more opinionated approach to data transformation. Google has Dataproc for Hadoop and Spark jobs. There are also dedicated Spark-as-a-Service options like Qubole and Databricks.
Load and Transform
On the other hand, raw data can be loaded directly into the warehouse and then transformed into the model. This approach makes creating and updating dimensions and de-duplicating fact tables easier. However, it also requires a lot of processing power on the warehouse side. Luckily there are several warehouses that meet that requirement and more on the market.
- Snowflake: The hot new thing in data warehouses, Snowflake offers a product that is infinitely scalable in every sense of the term. Data is stored in S3 or GCS, so there is effectively no limit on the amount of data you can store. Processing is done by disparate warehouses that can be sized according to their task: exploratory analysis can be done on an X-Small instance while a full table refresh ETL process uses a Medium instance and a Data Science model runs on a 4X-Large instance.
- BigQuery: BigQuery is Google’s managed data warehouse, and offers all of the features Snowflake has without thinking too hard about them. Storage is unlimited and processing power is effectively unlimited (although there are some limits that become abundantly obvious with large enough jobs.) BigQuery is more opinionated with their SQL dialect and discourage INSERT statements in favor of their API-driven load statements, but the result is the same.
- Redshift: Old reliable, Redshift has been available since 2013. Its age has pros and cons: it is very mature and ubiquitous, if you have a problem with Redshift there are probably 20 Stack Overflow questions with solutions for it. On the other hand, new features are very slow to be released because it has such high expectations for stability. Redshift recently added RA3 nodes which allow storage and compute to be decoupled, so clusters no longer need to have nodes added just because storage space is running out. Between RA3 and Spectrum, Redshift is keeping up with the competition and is still a viable product for infinite scalability if speed can be sacrificed for stability.
No matter the warehouse, dbt is making great strides in making ELT cross-platform and pragmatic. dbt would be my tool of choice for transformation logic.
Why Not Both?
It is rare that any large-scale data platform is going to have every data source fit neatly into either of the two boxes detailed above. The ideal solution would be to support both:
- A Spark- or Hadoop-based pre-processing tool to handle batches of large stand-alone data sets that don’t need a lot of modeling. For example, web server logs. The final destination for this raw data need not be the warehouse, some summarizing could be preformed to save space and encourage users to not query the raw event logs using a warehouse that isn’t designed for it.
- A dbt-based ELT process to handle batches of relational data that fit into a traditional star schema. For example, orders and transactions. The final destination for this transformed data is the warehouse.
Orchestration
There are a ton of exciting orchestration tools being built right now because, let’s face it, the last generation of scheduling and orchestration tools were not fantastic. Below are the options I am aware of and excited about.
- Airflow: Airflow rose like a rocket from an open source side-project at AirBnB to a top-level Apache project in a matter of a few years. It is currently the go-to standard for ETL orchestration and has a lot of good things going for it – a huge community, fantastic motivated maintainers, and a rich set of python tools. Airflow can also be deployed as a managed service using GCE Cloud Composer, Amazon MWAA, or Astronomer.
- Dagster: Dagster is another Python-based orchestration tool that implements some opinionated paradigms about how pipelines should be built. Like Airflow, pipelines are defined in Python rather than using configuration files. Dagster is designed to run the ETL code itself, as opposed to Airflow where the tide is shifting to using container-based operations. Dagster does not have a managed offering that I am aware of, so deployment would need to be self-managed. One major pro of Dagster is it is not a scheduling engine, which would lend itself nicely to an event-driven platform in which batches are scheduled at any interval, rather than on a fixed schedule like the rest of these tools.
- Prefect: Prefect is an orchestration tool designed to be run as a managed service. While they do have an open source version, to unlock the potential of the platform the managed version is a must. Like Airflow and Dagster, pipelines are defined in python and pipelines are designed to be coupled with ETL code.
- Argo: Argo is a Kubernetes-native orchestrator and scheduler. Argo uses YAML files for pipeline declaration, which means you lose some of the dynamic generation capabilites of code-based pipelines, but it also means your orchestration is fully decoupled from your ETL code.
Since the orchestration tool ecosystem is being distrupted so rapidly right now, at this moment I would prefer to choose a system where strong decoupling is possible. If your orchestration tool is just being used to schedule tasks in a container environment, it is very easy to move to the next great tool to come along with very low switching cost.
Alerting and Monitoring
Even resilient and well-architected pipelines break sometimes. Alerting and monitoring tools are critical to catching problems early and fixing them quickly.
Alerting
There are a ton of great alerting options, even some built in to the orchestration tools, which let you flexibly and intelligently send alerts to the team when things are going wrong.
- Pager Duty is a SaaS product that sends notifications to on-call engineers.
- Amazon SNS is an API provided by Amazon that sends notifications through email or SMS.
- Datadog Monitors is a service provided Datadog that sends alerts when metrics are in dangerous zones. This is a nice complimnetary service to their excellent monitoring offering.
Monitoring
I’ll separate monitoring into two types: monitoring infrastructure, and monitoring quality.
For monitoring infrastructure, the cloud providers have built-ins which work (Cloudwatch, Cloud Monitoring), but the player to beat in the space is Datadog. In addition to industry-leading monitoring and dashboarding, they offer alerting and log storage and tracing and even monitor serverless functions.
For monitoring data quality, I like Sisense to be able to quickly spin up dashboards using pure SQL. Redash is a self-hosted and open-source option that provides the same functionality, but Sisense is managed and polished.
Putting it all together
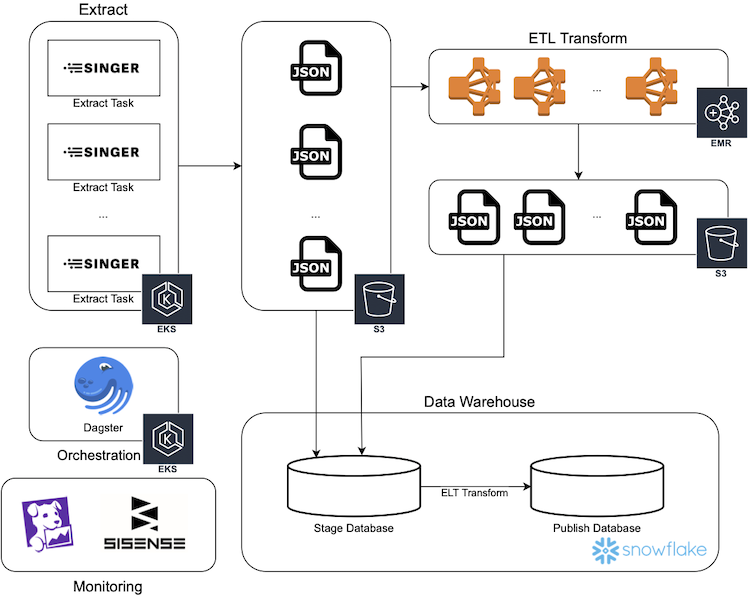
This diagram illustrates an implementation of a modern ETL platform using AWS services.
The solution described here meets our criteria:
- Managed. No servers need to be spun up and maintained, everything is serverless, managed, or SaaS.
- Infinitely scalable. Aggressively buying in to Kubernetes and auto-scaling easily lets capacity increase on the extract side, EMR and Snowflake are inherently scalable and even offer auto-scaling options for a no-thought solution.
- Modular. The design of the extract process allows extracts to operate independently. Our two-legged transform allows data to be handled the smartest way for each individual data source.
- Batch. Batch size can be adjusted at the scheduler level and the rest of the pipeline will scale accordingly.
- Modeled. Snowflake tables can be modeled to match the source system or designed in a traditional star or snowflake schema.